En este tutoríal vamos ha mostrar como realizar un POOL de conexiones para tener centralizada nuestra conexión a una base de datos MySQL, hay que tener en cuenta que este proceso se realiza totalmente igual si queremos conectarnos a ORACLE o a cualquier otra base de datos, esto nos evitara hacer una conexión nueva cada vez que queramos hacer una consulta nueva a la base.
Antes de empezar vamos a utilizar las siguientes herramientas:
Vamos a tener creada previamente en MySQL una base de datos llamada “prueba” y dentro de ella una tabla llamada “roles” con dos columnas con las filas de datos que usted prefiera ingresarle a esta tabla, este detalle pasa por cuenta de la persona que sigue este tutorial.
¿Pero qué es un Connection Pool o Pool de conexiones?
Un JDBC connection pool es un grupo de conexiones reutilizables que el servidor de la aplicación mantiene para una base de datos en particular. Cuando una aplicación cierra una conexión, regresa a la piscina. Las conexiones agrupadas reducen el tiempo de la transacción al conectarse a una base de datos por medio de compartir el objeto de acceso a la conexión a la base de datos, esto a su vez evita una nueva conexión física o crear cada vez una conexión nueva.
Al ejecutar esto es lo que pasa cuando una aplicación se conecta a la base de datos.
1. Lookup JNDI nombre de los recursos de JDBC. Para conectar a una base de datos, la aplicación busca el JNDI nombre del recurso de JDBC (Data Source) asociado con la base de datos. El API de JNDI permite a la aplicación localizar el recurso de JDBC.
2. Localizar el JDBC connection pool. El recurso de JDBC especifica qué piscina de conexiones va a usar. La piscina define los atributos de conexión como la base de datos nombre (el URL), nombre del usuario, y contraseña.
3. Recupere la conexión del connection pool. El servidor de la aplicación recupera una conexión física de la piscina de conexiones que corresponde a la base de datos. Ahora que la aplicación esta conectada a la base de datos, la aplicación puede leer, modificar y agregar los datos a la base de datos. Las aplicaciones acceden la base de datos haciendo las llamadas al API de JDBC.
4. Cerrado de la conexión. Cuando el acceso a la base de datos a terminado, la aplicación cierra la conexión. El servidor de la aplicación devuelve la conexión a la piscina de conexión. Una vez regresada a la piscina, la conexión está disponible para una próxima aplicación.
Nombre JNDI. Cada recurso tiene un único nombre de JNDI que especifica su nombre y situación. Porque todo el recurso que los nombres de JNDI están en el contexto del java:comp/env, los nombres JNDI de un recurso de JDBC se espera en el contexto del java:comp/env/jdbc.
Creación de un Nuevo Proyecto JSF en NetBeans 6.0
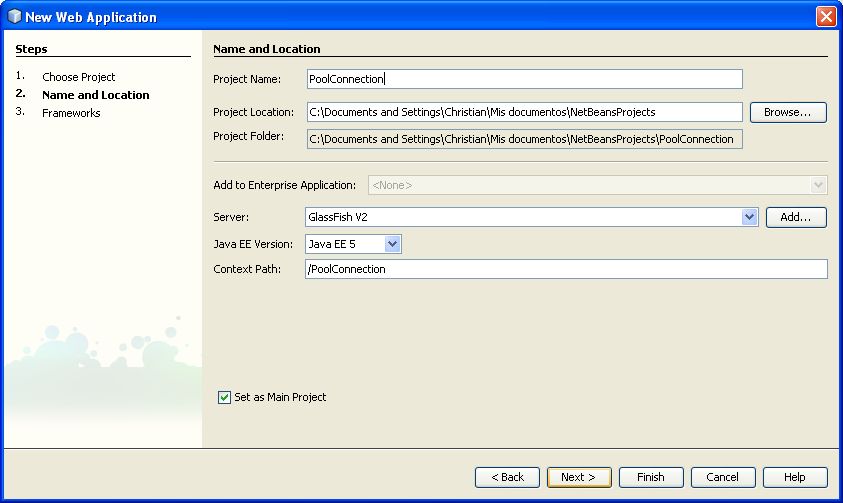
Como primer paso vamos a crear un nuevo proyecto de JSF, vamos a file -> New Poyect -> Web -> Web Application -> y clic en Next

Le ponemos un nombre en este caso le vamos a poner “PoolConnection” y luego clic en Next

Elegimos el Framework que vamos a utilizar “Visual Web JavaServer Faces” y no cambiamos nada más, clic en Finish.

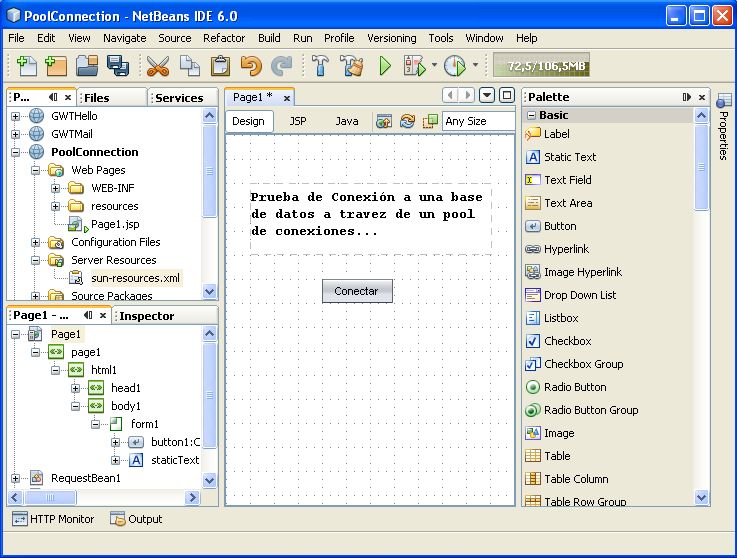
Una vez dentro de la parte de diseño de NetBeans vamos a arrastrar de la paleta un botón “Button” el cual va a ser el que nos conecte con la base MySQL y le vamos a poner de nombre conectar… Con esto realizado vamos a pasar a preparar la conexión a la base con la que vamos a trabajar.
Creación del Conector para la Base de Datos
Primero tenemos que ir a la parte de servicios (Ctrl + 5) en NetBeans y en Databases damos un clic derecho y ponemos en la opción de New Connection…

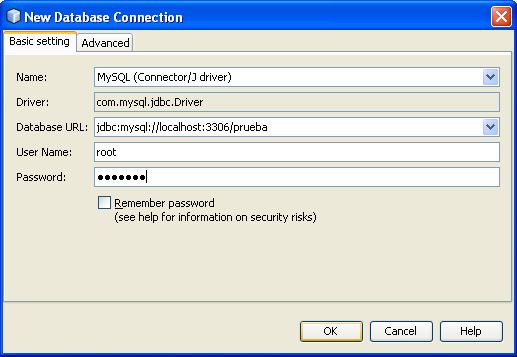
En la ventana de New Database Connection vamos a poner lo siguiente:
Name: MySQL (Connector/J driver)
Driver: com.mysql.jdbc.Driver
Database URL: jdbc:mysql://localhost:3306/prueba
En esta parte ponemos el host donde va a correr la aplicación que va a ser en “localhost”, al poner el puerto debemos tener cuidado porque el puerto 3306 es el puerto por defecto de MySQL, pero debemos ponerle el puerto que le pusimos en la instalación de MySQL si por si acaso lo cambiamos, y ponemos el nombre de la base a la que queremos tener acceso que en este caso va a ser “prueba”…
Por ultimo ponemos el User y el Password con el cual entramos a MySQL… Si queremos que recuerde NetBeans el Password le ponemos Remember Password caso contrario no (No es recomendable hacerlo por problemas de seguridad) y terminamos presionando OK.

Nos aparecerá una nueva base en el recuadro de Servicios, podremos conectarnos a ella y revisar los datos.

Creación del Pool de Conexiones para nuestro proyecto.
Lo que vamos a hacer primero es ir a File --> New File o directamente (Ctrl + n), en la ventana de New File, en Project escogemos el proyecto con el que estamos trabajando en nuestro caso “PoolConnection”, en el lado izquierdo en Categories vamos a escoger “GlassFish” y al lado derecho en File Types vamos a escoger la primera opción que es “JDBC Connection Pool” y clic en Next.

En la siguiente ventana nos pide como campo obligatorio o requerido un nombre para el pool de conexiones, le podemos dejar el que nos pone por defecto o simplemente lo cambiamos, nosotros lo vamos a dejar por defecto.
En el siguiente casillero de Extract from Existing Connection escogemos el conector que realizamos anteriormente para nuestra base de datos, y damos clic en Next.

En la siguiente ventana nos aparece Datasource Classname con un nombre bastante largo, este esta determinado por la conexión seleccionada anteriormente, nosotros lo vamos a dejar por defecto, le vamos a poner una descripción, en la tabla de propiedades podemos revisar los datos de ingreso a la base, para comprobar que estén correctos y terminamos dándole un clic en Next. (Si deseamos modificar las propiedades por defecto de la conexión, nosotros podemos cambiarlas luego editando el archivo sun-resources.xml, que se encuentra en la carpeta Server Resources de nuestro proyecto).
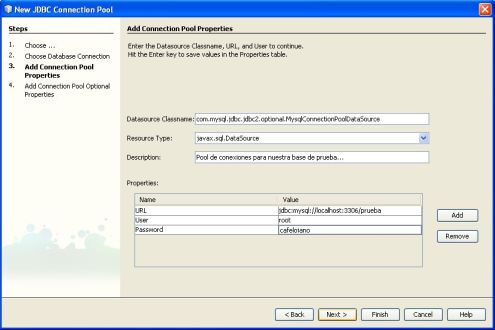
En la última Ventana que nos aparece con muchos campos todos los dejamos por defecto y ponemos un clic en Finish, con esto ya tenemos realizado nuestro pool de conexiones…
Acceder al Connection Pool desde una clase de Java
A través de este proceso podremos obtener un DataSource.
Lo primero que tenemos que hacer es crear el acceso a la base, vamos al código de la aplicación desde la cual queremos acceder a la base de datos, hacemos un clic derecho en el editor à escogemos Enterprise Resources à Use Database

Nos aparece la ventana para escoger la base de datos, hacemos un clic en Add, nos aparecerá una nueva ventana para configurar el Data Source, le ponemos un Nombre de Referencia en este caso le vamos a poner “conBasePrueba”, luego escogemos el Project Data Source como no tenemos creado un data source anterior, le ponemos clic en Add y se nos vuelve a abrir una nueva ventana, Create Data Source en el JNDI Name le ponemos el mismo nombre anterior “conBasePrueba” y elegimos el conector de la base a la que vamos a acceder, finalmente damos un clic en OK…

Regresamos a la ventana anterior y ya se nos carga el nombre de DataSource que ingresamos y creamos anteriormente y damos un clic en OK para confirmar…

Finalmente regresamos a la ventana de Choose DataBase ya se nos cargara la referencia a la base de datos y confirmamos haciendo un clic en OK…
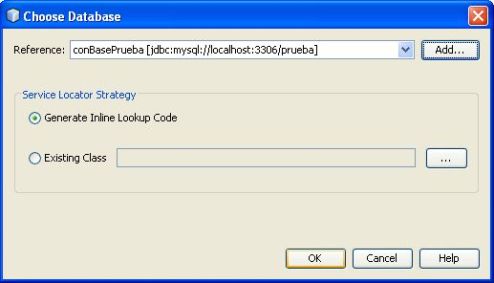
Con este último paso estamos listos para realizar una prueba de conexión desde el código…
Probemos nuestro Pool con una conexión rápida.
Vamos hacer una prueba rápida de conexión y vamos a visualizar por consola nuestro resultado, regresaremos a nuestra interfaz de Diseño de NetBeans y vamos a hacer doble clic en el botón que colocamos al inicio de este tutorial, nuestro proyecto se ve más o menos así ahora.

Una vez hecho doble clic en el botón, esta acción nos lleva al código de la aplicación, directamente al método del botón button1_action() el cual lo vamos a programar en este momento para hacer la conexión nuestro código debería quedar así.
[sourcecode language='java']
public String button1_action() {
Connection con = null;
try {
InitialContext ic = new InitialContext();
//en esta parte es donde ponemos el Nombre
//de JNDI para que traiga el datasource
DataSource ds = (DataSource) ic.lookup("java:comp/env/conBasePrueba");
con = ds.getConnection();
Statement st = con.createStatement();
System.out.println("Se ha realizado con exito la conexión a MySQL");
//el resultSet es el encargado de traer los datos de la consulta
ResultSet rs = st.executeQuery("select * from roles");
while(rs.next()){
System.out.println(" "+rs.getString(1)+" "+rs.getString(2));
}
}catch (SQLException ex) {
Logger.getLogger( Page1.class.getName() ).log(Level.SEVERE, null, ex);
}catch (NamingException ex) {
Logger.getLogger( Page1.class.getName() ).log(Level.SEVERE, null, ex);
}finally {
try {
con.close();
System.out.println("Conexion Cerrada con Exito...");
}catch (SQLException ex) {
Logger.getLogger( Page1.class.getName() ).log(Level.SEVERE, null, ex);
}
}
}
[/sourcecode]
Tenemos en nuestra base una tabla llamada “roles” la cual tiene 2 columnas, en el resultSet se almacena los datos obtenidos de la consulta y mientras haya datos en él se lo puede ir descomponiendo en columnas, con un while lo podemos ir recorriendo hasta llegar a la última fila…
Se debe hacer estas importaciones para que la aplicación pueda funcionar sin ningún problema aparte de las que ya aparecen al crear el nuevo proyecto.
[sourcecode language='java']
import java.sql.Connection;
import java.sql.ResultSet;
import java.sql.SQLException;
import java.sql.Statement;
import java.util.logging.Level;
import java.util.logging.Logger;
import javax.annotation.Resource;
import javax.faces.FacesException;
import javax.naming.InitialContext;
import javax.naming.NamingException;
import javax.sql.DataSource;
[/sourcecode]
Tutorial creado por:
christmo
 [/caption]
[/caption]![\includegraphics[angle=0, width=0.5\textwidth]{fig01-01.eps}](http://www.bioestadistica.uma.es/libro/img106.gif)
![\includegraphics[angle=-90, width=0.5\textwidth]{fig01-02.eps}](http://www.bioestadistica.uma.es/libro/img107.gif)
![\includegraphics[angle=-90, width=0.6\textwidth]{fig01-03.epsi}](http://www.bioestadistica.uma.es/libro/img108.gif)

![\includegraphics[angle=-90, width=0.6\textwidth]{fig01-04.epsi}](http://www.bioestadistica.uma.es/libro/img112.gif)
![\includegraphics[angle=0, width=0.5\textwidth]{fig01-05.eps}](http://www.bioestadistica.uma.es/libro/img113.gif)